




(... भाग 1 से जारी) ग्लोबलाइजेशन, इंटरनेशनलाइजेशन और लोकलाइज़ेशन 2. g11n, i18n, और l10n जब हम शुरुआत करते हैं तो हमें कुछ ऐसे शब्दों -...
(...भाग 1 से जारी)
ग्लोबलाइजेशन, इंटरनेशनलाइजेशन और लोकलाइज़ेशन
2. g11n, i18n, और l10n
जब हम शुरुआत करते हैं तो हमें कुछ ऐसे शब्दों - g11n, i18n, और l10n - का भी सामना करना पड़ता है. वस्तुतः ये शब्द उन लोगों के कार्यक्षेत्रों से जुड़े हैं जो कंप्यूटर को अपनी भाषा में बदलना चाहते हैं और ऐसे कार्य में संलग्न हैं. इन शब्दों का पूर्ण रूप क्रमशः ग्लोबलाइजेशन, इंटरनेशनलाइजेशन और लोकलाइज़ेशन है लेकिन कंप्यूटर की दुनिया में इसका अर्थ ठेठ सामान्य अर्थ से नितांत अलग है और इसे जानना सबसे पहले जरूरी है.
विकीकोश (Wiktionary) के अनुसार अन्तर्राष्ट्रीयकरण, i18n, यानी इंटरनेशनलाइजेशन उत्पाद को अन्तर्राष्ट्रीय बाज़ार के उपयुक्त बनाने के लिए किया गया कार्य या प्रक्रिया है जिसके अंतर्गत ख़ासकर पाठ संवाद को आसानी से अनुवाद योग्य बनाया एवं ग़ैर लैटिन वर्ण (कैरेक्टर) वाले सेट के समर्थन को सुनिश्चित किया जाता है.
उसी तरह, स्थानीयकरण, l10n, का मतलब उत्पाद को किसी खास राष्ट्र या क्षेत्र के उपयोग के लिए उपयुक्त बनाने का कार्य या प्रक्रिया है, विशेष रूप से उस देश या क्षेत्र की भाषा में अनुवाद कर, और यदि जरूरी हुआ तो ग़ैर लैटिन वर्ण (कैरेक्टर) वाले सेट के समर्थन को सुनिश्चित किया जाता है. यह एक प्रकार से उत्पाद की भौतिक संरचना के बारे में पूर्णतया नए रूप में विचार करने की तरह है. संक्षिप्त शब्द l10n जिसमें एक और शून्य संख्या है जो लोकलाइज़ेशन के पहले व आखिरी अक्षर यानी l व n के बीच के दस अक्षरों को प्रतिरूपित करता है. यहाँ l व n प्रायः छपाई के छोटे अक्षरों में लिखा रहता है. चूँकि ब्रिटिश अंग्रेज़ी में localization को localisation लिखा जाता है इसलिए ऐसा किया जाना दो रूप में काम करता है. एक तो किसी प्रकार की वर्तनी संबंधी अनिश्चितता को दूर करता है और दूसरे लिखने में कम समय लगता है. यही तर्क g11n और i18n के लिए लागू होता है.
![clip_image002[3]](http://lh6.ggpht.com/-wjrnh-aJGiA/UyFsOtFaDsI/AAAAAAAAXlw/p151Cuf24Xg/s1600-h/clip_image002%25255B3%25255D%25255B2%25255D.jpg "clip_image002[3]")
स्रोतः विकीपीडिया
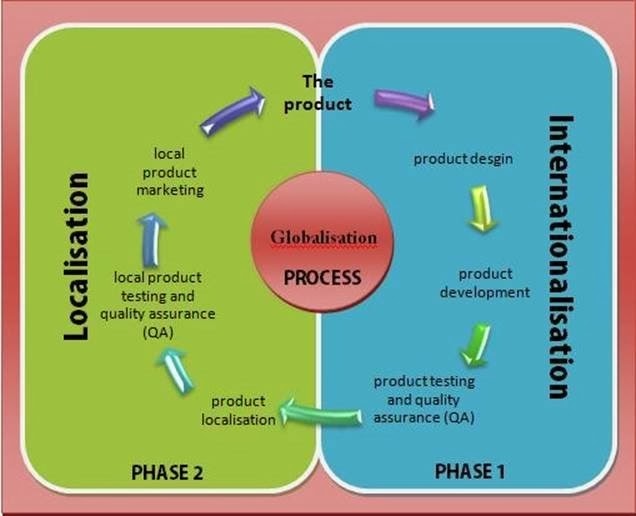
भूमंडलीकरण यानी g11n मतलब मूल भाषा के बनिस्बत, जिस भाषा में सॉफ़्टवेयर का जन्म हुआ है, अन्य भाषाओं में सॉफ़्टवेयर उत्पाद की उपलब्धता को सुनिश्चित करना है. क्योंकि सॉफ़्टवेयर के क्षेत्र में अमेरिका का संबंधित आकाशगंगा पर लगभग एकाधिकार है, इसलिए मूल भाषा पारंपरिक रूप से अमेरिकी अंग्रेज़ी (en_US) ही होती है. विशेष कर 1990 के दशक से दुनिया में भूमंडलीकरण एक घरेलू शब्द हो गया है. भूमंडलीकरण शब्द जिसका इस्तेमाल मुख्य रूप से मीडिया में किया जाता है, सामान्यतया आर्थिक भूमंडलीकरण की बात करता है. हम दुनिया को नियमित रूप से सिकुड़ते हुए देख रहे है. और इसलिए भूमंडलीकरण की प्रक्रिया का मतलब पूरी दूनिया के बीच संप्रेषणीयता की भी है.
अन्तर्राष्ट्रीयकरण और स्थानीयकरण उत्पादों को अनुकूल बनाने का जरिया है, यथा -ग़ैर स्थानीय माहौल के लिए यथा - प्रकाशन, हार्डवेयर अथवा सॉफ़्टवेयर विशेष रूप से दूसरे मुल्कों और तहजीबों के लिए. अन्तर्राष्ट्रीयकरण और स्थानीयकरण के बीच विभेद सूक्ष्म है लेकिन महत्वपूर्ण है. वास्तव में, अन्तर्राष्ट्रीयकरण हर जगह उत्पादों के संभावित उपयोग का एक प्रकार से अनुकूलन है, जबकि स्थानीयकरण क्षेत्र विशेष के लोकेल के लिए उपयोग हेतु विशिष्ट विशेषताओं के समावेशन की प्रक्रिया. लेकिन निश्चित रूप से यह दोनों प्रक्रियाएँ एक दूसरे की पूरक हैं और वैश्विक रूप से कार्य व सिस्टम के लिए संयुक्त रूप से अंजाम दी जानी चाहिए.
3. लोकेल, कैरेक्टर एनकोडिंग, फॉन्ट और कीमैप
लोकेल
वास्तव में लोकेल जैसी अवधारणा का जन्म ही अंतर्राष्ट्रीयकरण जैसे संबोधों के बाद आया. सॉफ़्टवेयर की परिभाषा मुताबिक़ लोकेल किसी देश से जुड़े क्षेत्र, दिनांक प्रारूप, मुद्रा, माप इकाई, लिपि और समय क्षेत्र के लिए स्थानीय रूप को शामिल करता है. ऐसे ढांचे से जुड़े होने पर सॉफ़्टवेयर के लिए दूसरी भाषा और सांस्कृतिक परिपाटी के अनुसार चलना आसान हो जाता है. कोई भी आदमी अपनी ज़रूरत मुताबिक़ लोकेल को चुन सकता है जो कि उनके लिए उपयुक्त हो. व्यक्ति के द्वारा चुने जाने पर सॉफ़्टवेयर प्रोग्राम कामकाज के लिए लोकेल परिभाषा फ़ाइलों को लोड करता है. इससे स्पष्ट है कि कोई जो लोकेल बनाना चाहता है उसे लोकेल परिभाषा फ़ाइल बनानी होगी जहाँ किसी देश से जुड़े क्षेत्र, दिनांक प्रारूप, मुद्रा, माप इकाई, लिपि और समय क्षेत्र के लिए स्थानीय नाम जैसी सभी सूचनाएँ इकट्ठी एक जगह पर होंगी. लोकेल परिभाषा फ़ाइल में वे सारी चीजें शामिल होगी जो localedef कमांड के द्वारा इसे द्विपदीय लोकेल डेटाबेस में बदलने के लिए जरूरी है. लोकेल फ़ाइल की सबसे खास बात है कि इसके कारण बिना कोई बदलाव के सॉफ़्टवेयर को अंतर्राष्ट्रीयकृत करने में सहूलियत होती है.
लोकेल सूचना में बोली जाने वाली भाषा का नाम व पहचानकर्ता को भी शामिल करता है. पहचानकर्ता को लोकेल के बारे में सूचना इकट्ठा करने में प्रयोग किया जाता है. यह पहचानकर्ता एक 32-बिट पूर्णांक है जो चार भागों में बंटा हुआ होता है. पहला दो हिस्सा जहाँ भाषा को बताती है वहीं बचा दो हिस्सा पाठ छांटे जाने के क्रम को बताती है. ज़ाहिर है लोकेल दिनांक, मुद्रा आदि के नामों के अलावा यह भी बताती है कि किस छांटन क्रम का प्रयोग किया जाना है.
इसके अलावे लोकेल का नामकरण भी जरूरी है. लोकेल को भाषा, देश व वर्ण के समुच्चयों से पहचाना जाता है. नामकरण की परिपाटी इस प्रकार है:
{lang}-{territory}-{codeset}[@{modifier}]
जहाँ {lang} दो या तीन अक्षर के भाषा कोड का प्रयोग किया जा सकता है जो ISO 639:1988 और ISO 639-2[TLC4] के द्वारा परिभाषित है. आप पूरी की पूरी सूची इंटरनेट पर इस लिंक पर पा सकते हैं:
http://www.loc.gov/standards/iso639-2/php/code_list.php
इस सूची का कुछ जरूरी भाग इस पुस्तक में शामिल परिशिष्ट में देख सकते हैं - परिशिष्ट. लोकेल भाषा. इसके बारे में कोई और जानकारी और किसी प्रकार की समस्या होने पर विशेष जानकारी के लिए आप इस वेब पेज की मदद ले सकते हैं:
http://www.loc.gov/standards/iso639-2/
{territory} दो अक्षर का देश कोड है जो ISO 3166-1:1997 में परिभाषित किया गया है. आप इस कोड को ISO 3166 मैंटेनेंस एजेंसी [TLC5] से पा सकते हैं.
{codeset} लोकेल में उपयोग में आने वाले वर्ण सेट का विवरण देता है.
{modifiers} यह भाग वैकल्पिक है. यह लोकेल में और अधिक सूचना जोड़ता है जिसमें विकल्पों को अर्द्धविराम से अलग करके रखा जाता है.
इस प्रकार उदाहरण के लिए, "India" ("IN") में बोली जानेवाली "Hindi" ("hi") का लोकेल hi_IN.ISCII-DEV, जहाँ ISCII-DEV एनकोडिंग है.
लोकेल प्रबंधन
अपने लिनक्स सिस्टम में लोकेल को जानने के लिए सिर्फ़ टर्मिनल पर जाकर locale कमांड चलाना होता है. जब इस कमांड का प्रयोग बिना किसी वितर्क यानी आर्ग्यूमेंट के होता है तो लोकेल कमांड सभी लोकेल श्रेणियों के लिए मौजूदा लोकेल वातावरण का विवरण देता है. यदि कंप्यूटर en_US (अंग्रेज़ी अमेरिका) की दृष्टि से सेट है तो लोकेल के लिए टर्मिनल कुछ इस प्रकार से सूचना प्रदर्शित करता है:
![clip_image004[3]](http://lh5.ggpht.com/-1hPh_veYpHY/UyFsQ6pYM6I/AAAAAAAAXmA/zFMYQbMNWM4/s1600-h/clip_image004%25255B3%25255D%25255B2%25255D.png "clip_image004[3]") |
![clip_image006[3]](http://lh3.ggpht.com/-WzUEXJV39mo/UyFsSxEC9YI/AAAAAAAAXmQ/Wp7B7ICh2_w/s1600-h/clip_image006%25255B3%25255D%25255B2%25255D.jpg "clip_image006[3]") |
उसी प्रकार हिंदी लोकेल के लिए टर्मिनल यह आउटपुट देता है.
एक लोकेल का निर्माण
यदि आपकी भाषा के लिए लोकेल पहले से अब तक नहीं बनाया गया है और आप बनाना चाहते हैं या अपनी भाषा के लिए कुछ खास सांस्कृतिक व भौगोलिक कारणों से मौजूदा रूप से उपलब्ध से भिन्न लोकेल बनाना चाहते हैं तो आप ऐसा आसानी से कर सकते हैं. इसके लिए आपको इस अध्याय में सबसे पहले बतायी गई लोकेल परिभाषा फ़ाइल बनानी होगी. फिर यदि आपको अपना भिन्न वर्ण सेट परिभाषित करना है तो आपको charmap फ़ाइल बनानी होगी. फिर लोकेल परिभाषा फ़ाइल व चारमैप फ़ाइल को कंपाइल करके लोकेल बनाने की ज़रूरत भर है.
![clip_image007[3]](http://lh3.ggpht.com/-AG_j-czb8yM/UyFsUh6ng2I/AAAAAAAAXmg/n2HVoUvA5EU/s1600-h/clip_image007%25255B3%25255D%25255B2%25255D.png "clip_image007[3]")
आप अपने लोकेल नाम को स्वयं LANG वातावरण चर में सेट कर सकते हैं:
अपना लोकेल बनाने के बाद आपको उसे glibc में डालना है ताकि दूसरे भी आपके लोकेल को प्रयोग कर सके. इसके अलावे एक उपाय है कि आप glibc में मौजूद लोकेल सूची में पैच भी जोड़ सकते हैं. आप अपने नये या बदलाव किये लोकेल को Request For
Enhancement (RFE) के रूप में sourceware bugzilla [TLC8] में कर सकते हैं. अपना खाता बनाकर अपने नए लोकेल के लिए आग्रह यहाँ रखें.
http://sources.redhat.com/bugzilla/enter_bug.cgi?product=glibc
यहाँ से आपके आग्रह को स्वीकृति मिलने पर आपका लोकेल तैयार हो जायेगा. इसके बाद आप इसका प्रयोग कर सकते हैं. यह समझें कि लोकेल एक पहचानपत्र की तरह है जो सिस्टम आपको अपनी भाषा का प्रयोग शुरू करने के लिए मांगता है. अभी glibc में मौजूद समर्थित लोकेल सूची भी देख लें तो बेहतर होगा. यहाँ समर्थित लोकेल की सूची आप परिशिष्ट II पर देख सकते हैं.
वर्ण एनकोडिंग
चूँकि कोई भी कंप्यूटर किसी भी सूचना को संख्या के माध्यम से ही समझता है, इसलिए प्रत्येक वर्ण यानी कैरेक्टर को भी किसी अद्वितीय संख्या के रूप में मैप करना पड़ता है, जिसे ही मोटे तौर पर वर्ण एनकोडिंग कह सकते हैं. किसी भी सॉफ़्टवेयर के स्थानीयकरण के लिए उसे एक ऐसे एनकोडिंग को समर्थन देना होता है जो कि लक्ष्य भाषा के वर्ण को दिखा सके.
यूनीकोड का महत्व
आज ऐसी कई एनकोडिंग योजनाएँ चल रही हैं. इसमें ASCII, ANSI, UCS-2, UCS-4 और यूनीकोड सहित कई और शामिल हैं. लेकिन आज यूनीकोड काफ़ी लोकप्रिय है और इसने मानकीकरण के लिए बड़ा काम किया है और ख़ासकर ग़ैर लैटिन भाषी दुनिया के लिए वरदान की तरह है.
![clip_image009[3]](http://lh4.ggpht.com/-gYyYONlMPvQ/UyFsWUotojI/AAAAAAAAXmw/xYfMYSIv9rs/s1600-h/clip_image009%25255B3%25255D%25255B2%25255D.jpg "clip_image009[3]") |
![clip_image011[3]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjszPlac6JaaBVghxhsm7XUjgn1J_KpXy65irnjK2Joghh9TPvuQD8NrHedPMgtlGJeU8bkGHiUJ0LjLFzEc2Qr_SUwjYUpBCZt7VXhWUYtNtiw37ZcK8Bw7sJlhzpR-5w4XJmf/s1600-h/clip_image011%25255B3%25255D%25255B2%25255D.jpg "clip_image011[3]") |
देवनागरी लिपि के लिए यूनीकोड निर्धारित कोडप्वाइंट:
युनीकोड का सारा काम-काज युनीकोड कंसोर्शियम के द्वारा चलाया गया प्रयास है जिसमें दुनिया के सभी कैरेक्टर के लिए एकल कैरेक्टर रिपोर्ट्वायर बनाने की कोशिश की गई है. युनीकोड एक ग़ैर लाभकारी संस्था है. युनीकोड कैरेक्टर रिपोट्वायर के प्रत्येक कैरेक्टर के लिए एक अद्वितीय पूर्णांक मान देता है. यह अद्वितीय पूर्णांक कोड प्वाइंट कहलाता है और इस कोड प्वाइंट को कोड यूनिट की शृंखला से मैप कर दिया जाता है, जहाँ कोड यूनिट कोड स्मृति की इकाई है जो 8 बिट, 16 बिट या 36 बिट हो सकती है. इस मैपिंग को कैरेक्टर एनकोडिंग फ़ॉर्म कहा जाता है. किसी भी भाषा में कैरेक्टर के इनपुट व आउटपुट के लिए एनकोडिंग सूचना जरूरी होती है, इसलिए कैरेक्टर एनकोडिंग का स्थानीयकरण के लिए बहुत महत्व है.
यूनीकोड देवनागरी कोड चार्ट
आप आगे देवनागरी कोड चार्ट देख सकते हैं. इसी तरह से सभी भाषाओं के लिए कोड चार्ट दिए गए हैं. देवनागरी लिपि का प्रयोग करने वाली भाषाएँ इसी देवनागरी कोड चार्ट का प्रयोग करती हैं. यानी अब इसका प्रयोग हिंदी, संस्कृत, मराठी, नेपाली, मैथिली आदि भाषाओं के लिए किया जा सकता है. हालांकि मैथिली जैसी कुछ भाषाओं ने यूनीकोड में अपनी पुरानी प्रयोग की जाने वाली लिपियों मैथिली के संदर्भ में मिथिलाक्षर यानी तिरहुता के लिए कोड प्वाइंट देने के लिए आवेदन दे रखा है.
![clip_image013[3]](http://lh6.ggpht.com/-NCS3J9TrLJc/UyFsaXObmBI/AAAAAAAAXnQ/1lbk6m7wneM/s1600-h/clip_image013%25255B3%25255D%25255B2%25255D.jpg "clip_image013[3]") |
![clip_image015[3]](http://lh6.ggpht.com/-FBztE1P8APk/UyFsdPX0A9I/AAAAAAAAXng/5jqzqF73G0o/s1600-h/clip_image015%25255B3%25255D%25255B2%25255D.jpg "clip_image015[3]") |
फ़ॉन्ट
एक खास वर्ण सेट का विजुअल प्रतिनिधित्व फ़ॉन्ट कहलाता है. किसी वर्ण के लिए फ़ॉन्ट सामान्यतः चित्रों के एक सेट से बना होता है जिसे गिल्फ कहते हैं. गिल्फ पूरे के पूरे वर्ण को भी दिखा सकता है और वर्ण के किसी एक हिस्से को भी. यह परिस्थिति पर निर्भर करता है. फिर एक गिल्फ में एक से अधिक वर्ण भी हो सकते हैं. गिल्फ चूँकि वर्ण का विजुअल प्रतिनिधित्व करता है इसलिए संभव है कि सौंदर्यात्मक दृष्टि से वह अलग-अलग हो. कोई सीधा-सपाट हो सकता है तो कोई घुमावदार बनावट लिए.
फ़ॉन्ट के ज्ञान की हालांकि स्थानीयकरण के लिए सीधी ज़रूरत नहीं है, परंतु यदि वह भाषा पहले कभी कंप्यूटर से नहीं जुड़ी है तो ज़ाहिर है कि उसके लिए फ़ॉन्ट बनाना होगा. हालांकि फ़ॉन्ट बनाने का काम इस मामले के विशेषज्ञ करते हैं फिर भी सामान्य जानकारी यहाँ हम दे रहे हैं जिससे फ़ॉन्ट से जुड़े सामान्य तकनीकी पहलुओं से परिचित हुआ जा सके. फ़ॉन्ट से जुड़ी चीजों में निम्नलिखित महत्वपूर्ण हैं. विभिन्न गुणों के आधार पर फ़ॉन्ट को कई आयामों में बांटा जा सकता है - स्थिर चौड़ाई बनाम परिवर्तनीय चौड़ाई फ़ॉन्ट तथा सेरिफ बनाम सांस सेरिफ. फ़ॉन्ट से जुड़ी जरूरी सूचनाएँ हैं:
फ़ॉन्ट मेट्रिक: परिवर्तनीय चौड़ाई फ़ॉन्ट में स्थान परिभाषित करता है. फ़ॉन्ट के आकार जैसी सूचनाएं इसमें रहती हैं.
फ़ॉन्ट आकार: इसमें फ़ॉन्ट का खाका या आकार रहता है.
टाइपफेस: इसमें फ़ॉन्ट की शैली या डिजायन रहती है. बोल्ड, इटालिक आदि टाइपफेस के उदाहरण हैं.
सेरिफ फ़ॉन्ट के हर वर्ण के नीचे एक छोटा हुक सा रहता है. टाइम्स न्यू रोमन सबसे लोकप्रिय सेरिफ फ़ॉन्ट है. सैनसेरिफ में यह हुक नहीं रहता है और यह सीधा सपाट दिखता है. वेरदाना प्रसिद्ध सेनसेरिफ फ़ॉन्ट है. फ़ॉन्ट आकार यदि छोटा लेना होता है तो सेरिफ का प्रयोग बढ़िया रहता है. कर्निंग भी फ़ॉन्ट से जुड़ी शब्दावली में आता है जिसका अर्थ आस-पास के वर्ण को पठनीयता की दृष्टि से नजदीक या दूर ले जाना होता है.
फ़ॉन्ट के प्रकार:
बिटमैप फ़ॉन्ट
बिटमैप फ़ॉन्ट डॉट मैट्रिक्स है. बिटमैप को डॉट की सरणी के रूप में जमा किया जाता है. टर्मिनल विंडो, कंसोल, पाठ संपादक आदि में इसका प्रयोग बहुत प्रयोग होता है. इसे बड़ा या छोटा करना थोड़ा मुश्किल होता है.
आउटलाइन फ़ॉन्ट
आउटलाइन फ़ॉन्ट में किसी भी वर्ण को पंक्ति के सेट या वक्र के रूप में परिभाषित किया जाता है. इस फ़ॉन्ट को किसी आकार तक बड़ा या छोटा किया जा सकता है. टाइप 1 फ़ॉन्ट एडोब के द्वारा बनाया गया स्केलेबल फ़ॉन्ट है जो बड़े पैमाने पर लिनक्स उपयोक्ता द्वारा उपयोग किया जाता है. लेकिन टाइप 1 फ़ॉन्ट का मेट्रिक्स जटिल लिपियों के लिए उपयुक्त नहीं बैठता है. ट्रूटाइप फ़ॉन्ट को एप्पल द्वारा विकसित किया गया था लेकिन बाद में माइक्रोसॉफ़्ट ने इसके काम को काफ़ी फैलाया. यह फ़ॉन्ट (.ttf विस्तार युक्त) एक ही फ़ाइल में वितरित रहता है जिसमें आकार के साथ ही साथ मेट्रिक सूचना भी शामिल रहती है. यह प्रायः सभी प्लेटफ़ॉर्म के द्वारा समर्थित है. लिनक्स के अंदर भी अब यह लोकप्रिय होता जा रहा है.
ओपनटाइप फ़ॉन्ट
यह ओपनटाइप फ़ॉन्ट माइक्रोसॉफ़्ट व एडोब के संयुक्त प्रयास का नतीजा है जिसे अंतरराष्ट्रीयकरण के लिए जरूरी फ़ॉन्ट प्रारूप को पाने के लिए बनाया गया था. मूलभूत संरचना ट्रूटाइप के तरह की ही होती है लेकिन यह टाइप 1 के खाका को भी अपने लिए शामिल कर सकता है. ज़ाहिर है कि अंतरराष्ट्रीयकरण के लिए खास तौर पर तैयार किये जाने के कारण यह फ़ॉन्ट स्थानीयकरण के लिए काफ़ी बढ़िया होता है.
ट्रूटाइप फ़ॉन्ट माइक्रोसॉफ़्ट से जुड़े होने के कारण काफ़ी लोकप्रिय है और इसमें हिंटिंग फीचर का बेहतर उपयोग होता है. हिंटिंग का काम छोटे रिजॉल्यूशन पर ज़्यादा होता है. परंतु स्थानीयकरण के लिए ओपनटाइप फ़ॉन्ट ज़्यादा उपयोगी है.
कुछ महत्वपूर्ण देवनागरी फ़ॉन्ट सहित कई अन्य लिपियों के लिए आप फ़ॉन्ट यहाँ से डाउनलोड कर सकते हैं. उपयोग करने के पूर्व इससे जुड़ी शर्तों को पढ़ लें:
http://tdil.mit.gov.in/download/openfonts.htm
http://fedoraproject.org/wiki/Lohit
http://savannah.nongnu.org/projects/fontdudes
http://packages.debian.org/testing/x11/ttf-indic-fonts
http://savannah.gnu.org/projects/freefont
http://en.wikipedia.org/wiki/InScript_Typing
कुंजीमानचित्र
कुंजीमानचित्र का महत्व ग़ैर लैटिन भाषाओं के लिए होता है. जैसे हिंदी के कई उपयोक्ता जहाँ इंस्क्रिप्ट का प्रयोग करते हैं तो कई ध्वन्यात्मक कीमैप का. इंस्क्रिप्ट कुंजीपटल लेआउट भारत सरकार के द्वारा मानकीकृत किया गया है. लेकिन फिर भी कई लोग रोमन ध्वनि आधारित कीमैप को अंग्रेज़ी कुंजी पर अभ्यास रहने की वजह से प्राथमिकता देते हैं. इसी पर आधारित ध्वन्यात्मक लेआउट भी लोक्रपिय हुए हैं.
इंस्क्रिप्ट लेआउट देवनागरी:
![clip_image017[3]](http://lh6.ggpht.com/-NtmiJsMiItM/UyFsfKKsrJI/AAAAAAAAXnw/r11gvBKV6kw/s1600-h/clip_image017%25255B3%25255D%25255B2%25255D.png "clip_image017[3]")
इसी तरह के एक लोकप्रिय ध्वन्यात्मक कीमैप बोलनागरी को देखें:
![clip_image019[3]](http://lh5.ggpht.com/-DRZoXRfC5xE/UyFshOw_KCI/AAAAAAAAXoA/kuYNwE2zl-I/s1600-h/clip_image019%25255B3%25255D%25255B2%25255D.png "clip_image019[3]")
जरूरी लिंक:
http://www.microsoft.com/typography/WhatIsTrueType.mspx
http://www.math.utah.edu/~beebe/fonts/postscript-type-1-fonts.html
http://www.adobe.com/type/opentype/index.html

(राजेश रंजन)
राजेश रंजन विगत कई वर्षों से हिन्दी कंप्यूटरीकरण
के कार्य से जुड़े हुए हैं. वे अभी एक बहुदेशीय
सॉफ्टवेयर कंपनी रेड हैट में बतौर लैंग्वेज मेंटेनर हिन्दी
के रूप में कार्यरत हैं. वे कंप्यूटर स्थानीयकरण की कई
परियोजनाओं जैसे फेडोरा, गनोम, केडीई, ओपनऑफिस,
मोज़िला आदि से जुड़े हैं. साथ ही कंप्यूटर अनुवाद में
मानकीकरण के लिए चलाए गए एक महत्वाकांक्षी सामुदायिक
परियोजना फ़्यूल के समन्वयक भी हैं. इसके अलावे उन्होंने
मैथिली कंप्यूटिंग के कार्यों को भी अपनी देख-रेख में
मैथिली समुदाय के साथ पूरा किया है. वे प्रतिष्ठित मीडिया
समूह इंडियन एक्सप्रेस ग्रुप के जनसत्ता और लिटरेट
वर्ल्ड के साथ काम कर चुके हैं.हिन्दी पत्रकारिता में भारतीय जनसंचार संस्थान, नई दिल्ली
से स्नातकोत्तर डिप्लोमा पाने के पहले इन्होंने नेतरहाट विद्यालय,
साइंस कॉलेज, पटना और किरोड़ीमल कॉलेज, दिल्ली जैसे
जाने-माने संस्थानों में अध्ययन किया है. भाषाई तकनीक, इंटरनेट,
कंप्यूटर पर इनके लेखादि लगातार प्रकाशित होते रहते हैं.
कॉपीराइट © राजेश रंजन, सर्वाधिकार सुरक्षित.
क्रियेटिव कॉमन्स एट्रीब्यूशन शेयर एलाइक लाइसेंस के अंतर्गत.
(क्रमशः अगले भाग 3 में जारी...)
वाह ।
जवाब देंहटाएंआपकी इस प्रस्तुति को आज कि अल्बर्ट आइंस्टीन और ब्लॉग बुलेटिन में शामिल किया गया है। कृपया एक बार आकर हमारा मान ज़रूर बढ़ाएं,,, सादर .... आभार।।
जवाब देंहटाएंबहुत ही उपयोगी तथ्य बताये हैं, अभी तो हमें हिन्दी टंकण में कोई समस्या नहीं है पर जब यह प्रक्रियायें फलीभूत हो रही होंगी तो प्रवाह में कठिनता रही होगी।
जवाब देंहटाएंnamaskar, bandhuvar !
जवाब देंहटाएंmain gat 2 varsh se aarambh ke hindi tool se kaam kar raha tha. kal achanak wah band ho gaya.
kripaya, mujhe koi aisa phonetic transliteration tool bataiye jo aarambh ki hi tarah offline bhi kaam kar sake.
aapka aabhari rahoonga.
आपने बहुत अच्छी जानकारी हमारे साथ साझा की उसके लिए आपका धन्यबाद।
जवाब देंहटाएं